今天咱们来解读一个数据提取的模式化公式用法。
A2单元格是中文和数字的混合内容:兴发实业公司52001
现在需要提取A2单元格中右侧的数字。
这种数据有多种提取方式,今天咱们分享的是各版本都能使用的通用公式:
=-LOOKUP(1,-RIGHT(A2,ROW($1:$10)))
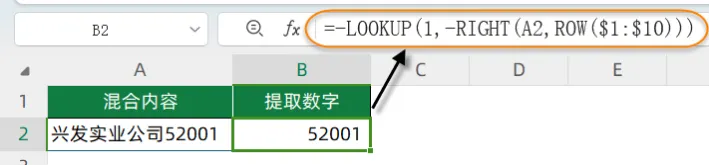
接下来就看看这个公式的运算过程:
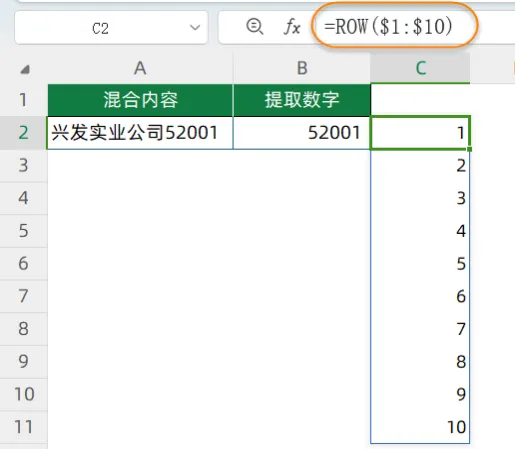
(1)先来看ROW($1:$10)部分,得到是1~10的序号:
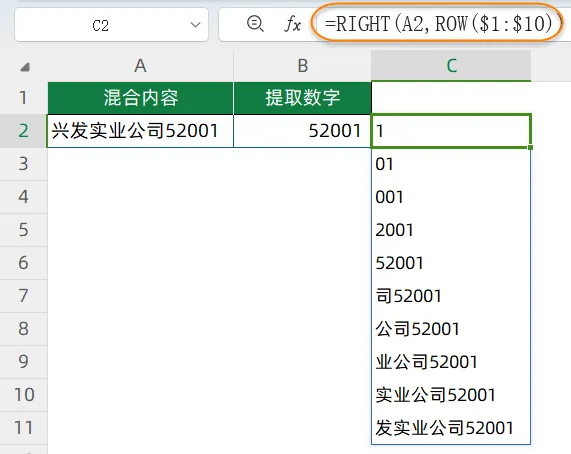
(2)再来看RIGHT(A2,ROW($1:$10))部分,从A2右侧分别提取出1~10字符:
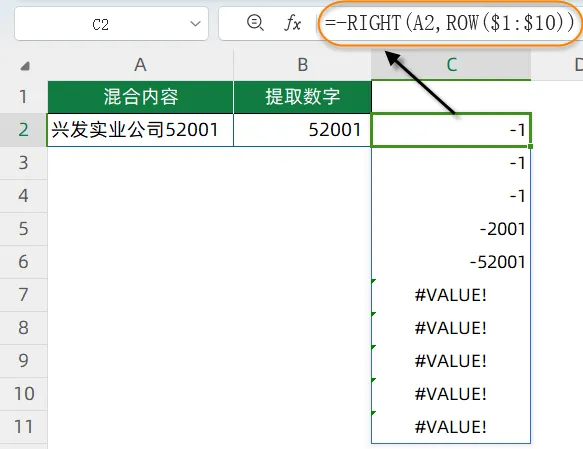
(3)接下来看这部分的结果 -RIGHT(A2,ROW($1:$10)),数字变成了负数,带有文字的变成了错误值:
最后使用LOOKUP函数来获取需要的数字。
LOOKUP函数有三个特点:第一个特点是要求查询区域必须升序进行排序。如果没有经过排序,LOOKUP函数也会认为排在数据区域最后的内容,是该区域中最大的。
第二个特点是当查找不到具体的查询值时,会以比查询值小、并且最接近查询值的内容进行匹配。
第三个特点是自动忽略查询区域(或数组)中的错误值。
回到本例中,LOOKUP函数用1作为查找值,在带有错误值和数值的内存数组中进行查找。由于找不到1,LOOKUP会忽略错误值返回最后一个数字“-52001”进行匹配。
最后再加上一个负号,把负数变成正数,就得到了最终的计算结果“52001”。
在字符串最左侧提取连续数字的模式化公式,也是一样的计算过程。只不过是把从最右侧提取字符的RIGHT函数变成了从最左侧提取字符的LEFT函数了:
=-LOOKUP(1,-LEFT(A2,ROW($1:$10)))
标签: Excel



