1、数据筛选
如下图,希望从左侧的信息表中,根据G2的条件,提取出符合条件的全部记录。
F5单元格输入以下公式,按回车。
=FILTER(A2:D14,C2:C14=G1)
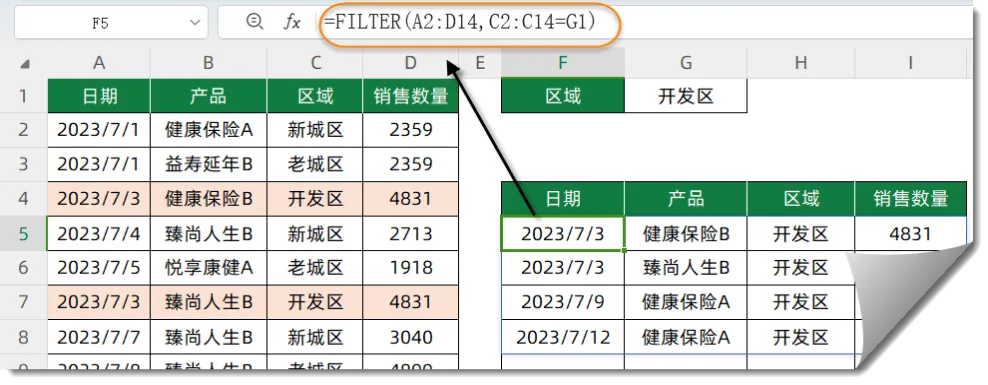
FILTER函数第一参数使用A2:D14作为筛选区域,筛选条件为C2:C14=G1,如果筛选条件的计算结果是TEUR或者不为0的数值,FILTER函数就返回第一参数中对应的整行记录。
2、指定条件的不重复记录
如下图,希望从左侧的信息表中,根据G1的条件,提取出符合条件的不重复产品记录。
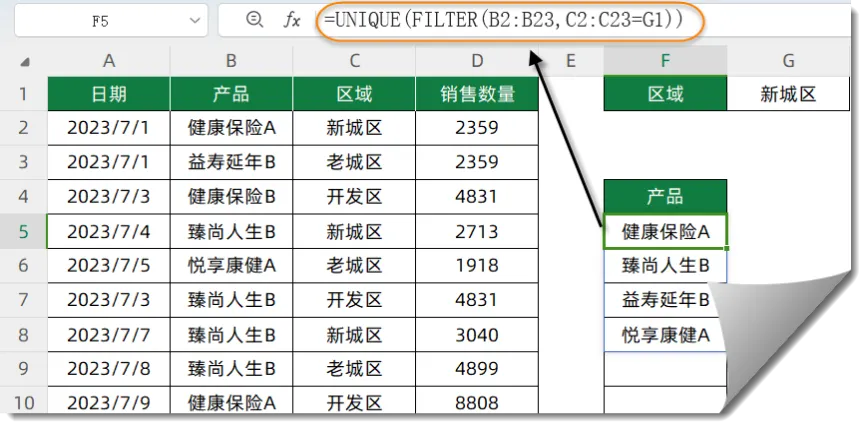
F5单元格输入以下公式,按回车。
=UNIQUE(FILTER(B2:B23,C2:C23=G1))
首先使用FILTER函数筛选出符合条件的全部产品列表,再使用UNIQUE函数去除重复项。
3、自定义排序
如下图,希望根据F列的职务对照表,对左侧的员工信息进行排序。
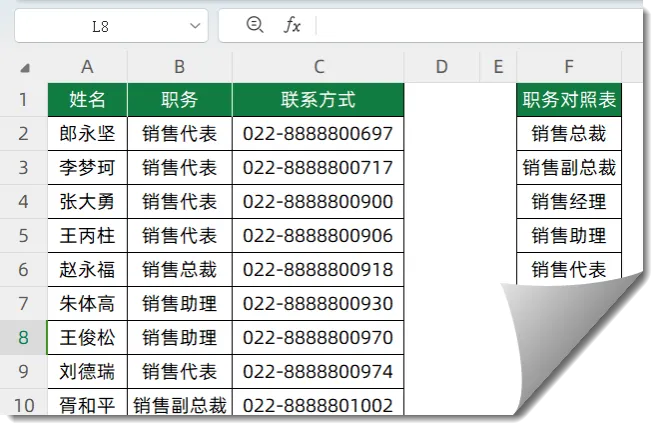
H2单元格输入以下公式,按回车即可。
=SORTBY(A2:B21,MATCH(B2:B21,F:F,))
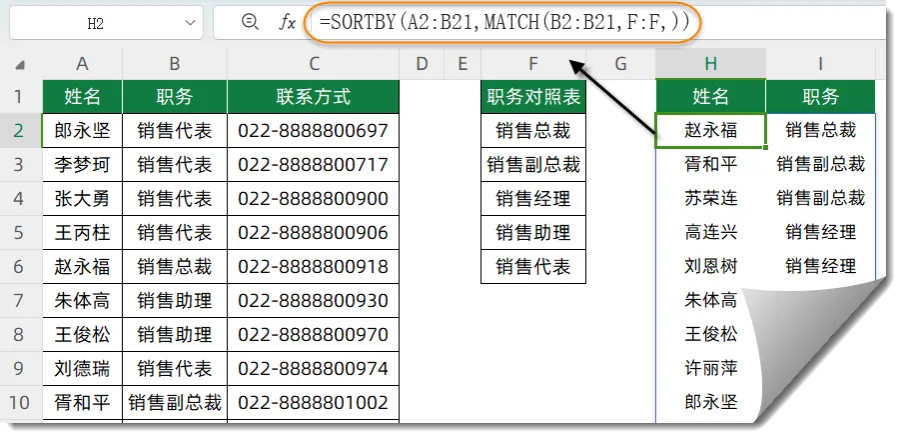
公式中的MATCH(B2:B21,F:F,)部分,分别计算出B2:B21单元格中的各个职务在F列中所处的位置。
接下来再使用SORTBY函数,根据这些位置信息对A2:B21中的内容进行排序处理。
4、二维表转换为数据列表
如下图所示,希望将A~E的二维表,转换为右侧所示的数据列表,部门和姓名分两列显示。

G2单元格输入以下公式,按回车。
=HSTACK(TOCOL(IF(B2:E5<>””,A2:A5,0/0),2),TOCOL(B2:E5,1))
公式由两个TOCOL函数组成。
先看第一部分TOCOL(IF(B2:E5<>””,A2:A5,0/0),2)。
使用IF函数进行判断,如果B2:E5不等于空白,就返回A2:A5中对应的部门名称,否则返回由0/0得到的错误值#DIV/0!:

接下来再使用TOCOL函数,忽略以上数组中的错误值将数组转换为一列。
再看公式中的TOCOL(B2:E5,1)部分,这部分的作用是将B2:E5中的姓名,在忽略空白单元格的前提下转换为一列。
最后用HSTACK函数将以上两个TOCOL的数组结果,按左右方向合并为一个数组。
5、自动增减的序号
如下图,在A2单元格输入以下公式,可以生成随着数据增加而变化的序号。
=SEQUENCE(COUNTA(B:B)-1)
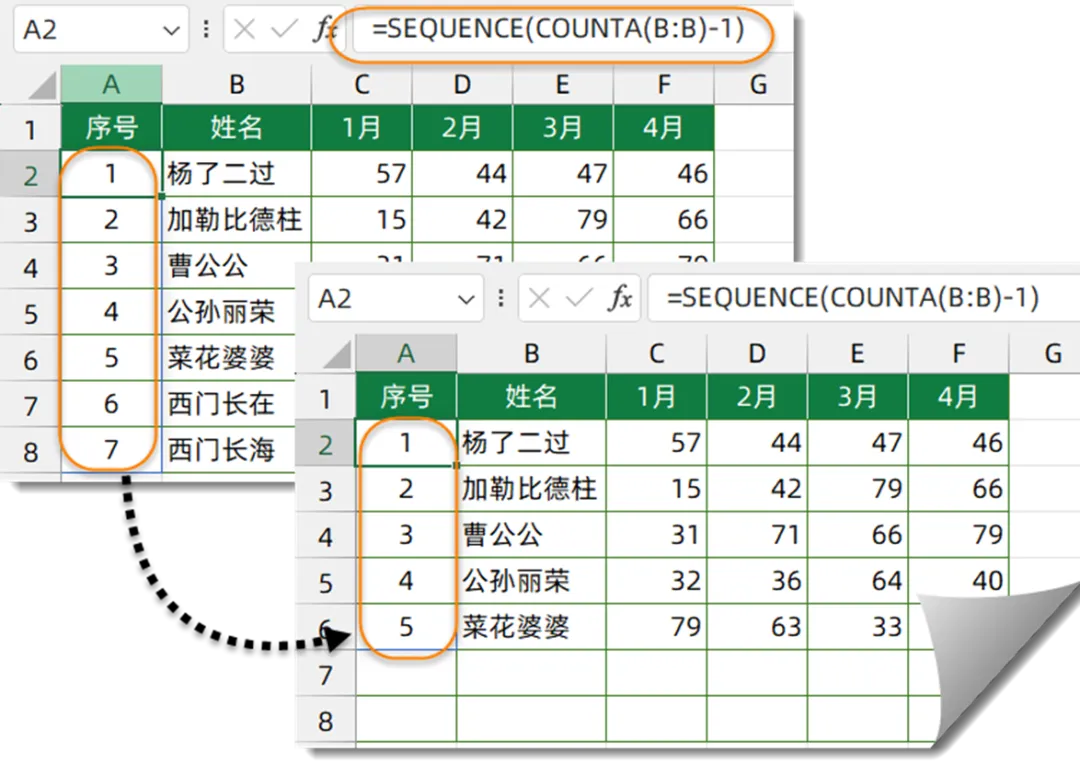
COUNTA(B:B)-1部分,计算B列非空单元格的个数。减去1,得到不包含标题行在内的实际记录数。
SEQUENCE函数用于生成指定行列的序列号。本例中,生成序号的行数由COUNTA(B:B)-1的结果来指定。也就是B列有多少行数据,SEQUENCE函数就生成对应行数的序号。
6、随机分组
如下图所示,希望将A列的姓名随机分成4组。

C2单元格输入以下公式,每按一次F9键,就可以得到四组随机排列的名单:=IFERROR(INDEX(SORTBY(A2:A21,RANDARRAY(20)),SEQUENCE(10,4)),””)
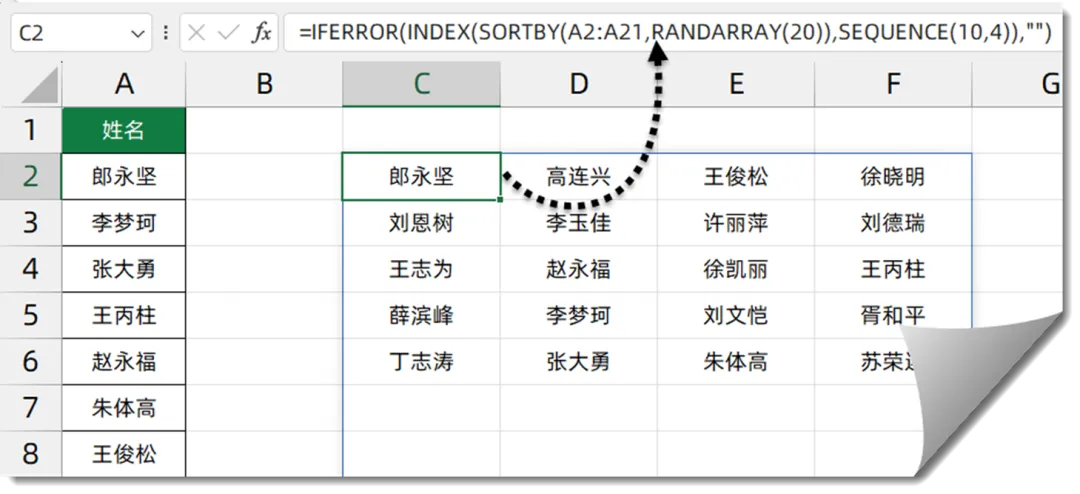
公式中的SORTBY(A2:A21,RANDARRAY(20))部分,先使用RANDARRAY(20)得到20个随机小数,再使用SORTBY以随机小数为排序依据对A列姓名进行随机排序。
SEQUENCE(10,4)部分用来生成10行4列的序列号。
INDEX函数根据SEQUENCE生成的序列号,从随机排序后的姓名中返回对应位置的内容。
最后,使用IFERROR函数屏蔽可能出现的错误值。



